이 연구에서는 구미시의 경제활동인구 및 취업자 수 예측을 위해 시계열 모델과 LLM을 활용한 두 가지 접근법을 비교했다. 데이터는 경제활동인구, 경제활동참가율, 취업자 수, 고용률 등 총 12개 변수로 구성된 142개 지역의 반기별 데이터를 기반으로 하며, 시계열 모델은 슬라이딩 윈도우 방식으로 데이터를 학습했다. 시계열 모델은 여성 경제활동의 불규칙성을 반영한 변수와 남성/여성 데이터를 모두 사용해 예측 정확도를 높였고, LLM은 산업 특성 및 정책 요인 등을 고려해 예측을 시도했다. 연구는 모델 성능 향상을 위해 도메인 지식과 feature engineering을 활용한 성능 개선을 제시하며, 하이브리드 모델 접근을 통해 예측 정확도 향상이 가능하다고 결론지었다.
1. 개발 목표

- 미래의 1개 시점을 예측하는 단기 예측 모델 학습
- 위의 표를 구성하는 항목들을 예측하며, 예측 대상 변수들은 다음과 같음
- 취업자(남성/여성/전체), 전체 고용률, 경제활동인구, 경제활동참가율
- 취업자(남성/여성/전체), 전체 고용률, 경제활동인구, 경제활동참가율
- 본문에서는 취업자 수(남자/여자/전체)와 경제활동인구(남자/여자/전체) 예측 모델에 대한 내용을 중점적으로 작성
2. 활용 데이터
- 경제활동인구, 경제활동참가율, 취업자수, 고용률에 대해 전체/남성/여성으로 구분된 총 12개 항목의 데이터를 학습에 활용
(* 데이터 출처: KOSIS(「지역별고용조사」, 통계청)) - 각 항목들은 2013년 상반기부터 2024년 상반기까지 수집된 23개(시점)의 반기별 데이터
- 전체 230개 지역(시/군/구) 중 데이터 수집 기간이 일치하지 않는 지역들을 제외하고 최종적으로 142개 지역의 데이터를 학습에 사용
3. 변수 선정
- 예측 대상 변수들의 계산식은 표1과 같음
| 변수 | 수식 |
|---|---|
| 경제활동인구(명) | 취업자+실업자 |
| 경제활동참가율(%) | (경제활동인구/만 15세 이상 인구)*100 |
| 취업자수(명) | 남성취업자+여성취업자 |
| 고용률(%) | (취업자수/만 15세 이상 인구)*100 |
- 경제활동인구를 계산할 때는 취업자 수와 실업자 수를 합산하며, 경제활동참가율은 이 경제활동인구를 만 15세 이상 전체 인구로 나누어 산출한다는 점을 파악
- 실업자 수와 실업률, 만 15세 이상 인구 수를 추가하여 테스트한 결과 실업자 수와 실업률은 주요 변수로 추가하고 만 15세 이상 인구는 모델 성능을 저하시켜 제외
- 데이터 수가 적고 반기 데이터임을 고려해 날짜 관련 변수는 추가하지 않고 총 14개의 변수의 순차적 패턴만을 학습하도록 함
- 여성의 경제활동 참여는 출산과 육아 등 생애주기적 요인으로 인해 불규칙한 패턴을 보이므로 예측의 정확도를 높이기 위해 비경제활동 관련 변수를 분석에 포함
- 따라서 예측에 활용한 최종 변수는 다음과 같음
| 모델 | 변수명 | 개수 |
|---|---|---|
| 남성 경제활동 예측 모델 | 경제활동인구(계, 남자, 여자) 경제활동참가율(계, 남자, 여자) 고용률(계, 남자, 여자) 취업자(계, 남자, 여자) 실업자(계) 실업률(계) |
14 |
| 여성 경제활동 예측 모델 | 경제활동참가율(여자) 비경제활동(여자, 15~29세, 30-49세, 육아) 경제활동인구(여자) 취업자(여자) 고용률(여자) |
8 |
4. 데이터셋 구성 방안
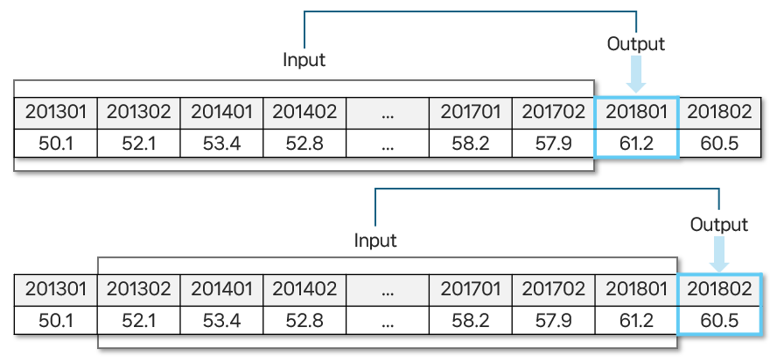
- 슬라이딩 윈도우 방식으로 10개의 연속된 시점을 입력값(Input)으로 사용하고, 그 다음 시점의 값을 출력값(Output)으로 하여 데이터셋을 구성
5. 모델 구축 결과
5.1 남성 경제활동 예측 모델
- 남성 데이터셋의 shape은 다음과 같음 (데이터 수, 시퀀스 수, 특성 수)
| 구분 | 내용 | shape |
|---|---|---|
| 학습용 데이터 | 구미시를 제외한 142개 지역 | X:(1846, 10, 14) y:(1846,1,14) |
| 테스트 데이터 | 구미시 데이터 | X:(13,10,14) y:(13,1,14) |
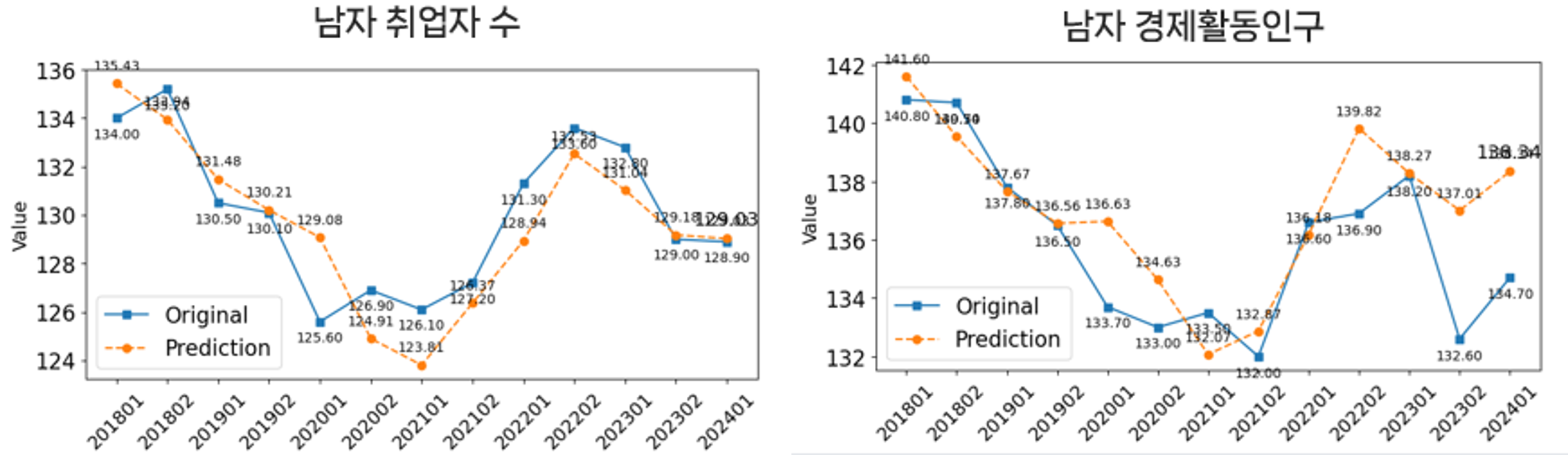
- 남성 경제활동 예측 모델 구축 시, 여성 관련 변수들을 함께 활용했을 때 예측 성능이 향상되어 분석에 포함
5.2 여성 경제활동 예측 모델
- 여성 데이터셋의 shape은 다음과 같음 (데이터 수, 시퀀스 수, 특성 수)
| 구분 | 내용 | shape |
|---|---|---|
| 학습용 데이터 | 구미시를 제외한 142개 지역 | X:(2414, 6, 8) y:(2414, 1, 8) |
| 테스트 데이터 | 구미시 데이터 | X:(17, 6, 8) y:(17, 1, 8) |
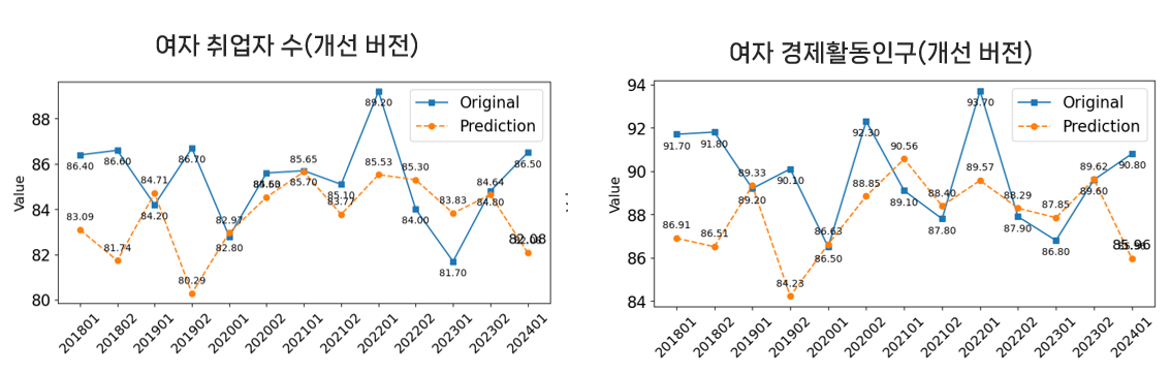
- 여성 경제활동 예측 모델의 경우, 각 변수들의 높은 변동성으로 인해 긴 시퀀스 사용 시 예측 정확도가 저하되는 현상이 관찰됨. 따라서 시퀀스를 6으로 설정하여 과거 데이터로 인한 노이즈를 최소화하고자 함
5.3 최종 모델
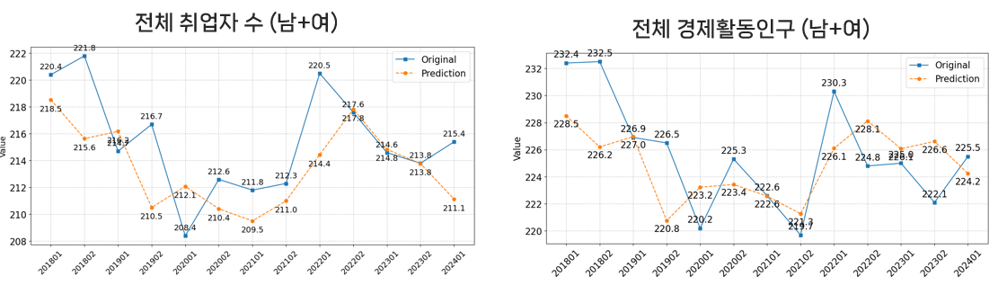
- 남성과 여성에 대한 각각의 경제활동 모델 결과를 결합하여 전체 취업자/인구에 대한 예측값을 산출함
6. LLM 활용 예측
- Claude 3.5 Sonnet을 활용하여 구미시 경제활동인구에 대한 독립적인 예측을 시도
- LLM은 지역 특성, 산업 동향, 정책적 요인 등을 종합적으로 고려 가능
- 다음 프롬프트를 활용하여 시계열 모델과 동일하게 1시점 예측을 수행
맥락:
대한민국 경상북도 구미시의 경제활동 데이터를 바탕으로 다음 시점의 주요 경제지표를 예측해야 합니다.
예측 필요 항목 (단위: 만명):
1. 경제활동인구_남자
2. 경제활동인구_여자
3. 취업자_남자
4. 취업자_여자
예측 시 준수사항:
1. 코드 작성이나 특정 알고리즘을 사용하지 말 것 - 논리적 추론을 통해 예측할 것
2. 제시된 시점까지의 데이터만 활용할 것 - 이후 시점의 정보는 배제할 것
3. 데이터셋 내 모든 변수 간의 상관관계를 고려할 것
4. 다음 요소들을 고려할 것:
- 구미시의 산업도시로서의 특성
- 경제적 요인들
- 정책적 요인들
고려해야 할 주요 사항:
- 구미는 전자/IT 제조업이 발달한 주요 산업도시임
- 지역 경제 정책과 산업 동향을 고려해야 함
- 계절적 패턴과 인구통계학적 추세를 반영해야 함
출력 형식:
예측값을 다음과 같은 파이썬 리스트 형식으로 제시할 것:
경제활동인구_남자 = [예측값]
경제활동인구_여자 = [예측값]
취업자_남자 = [예측값]
취업자_여자 = [예측값]
- 각 예측 결과는 다음과 같음
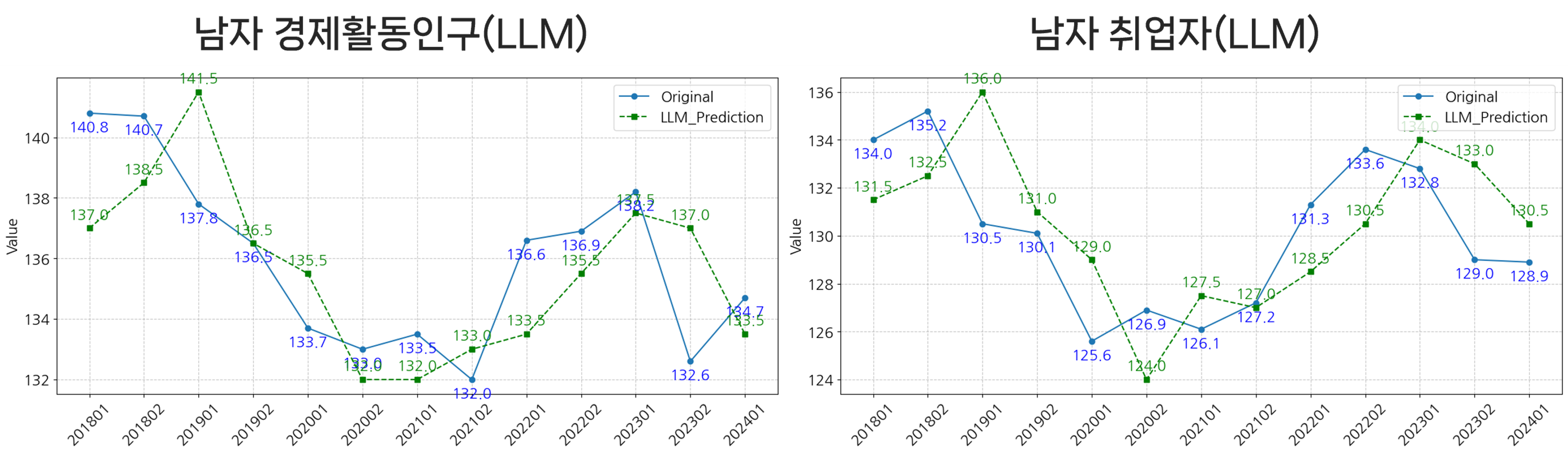
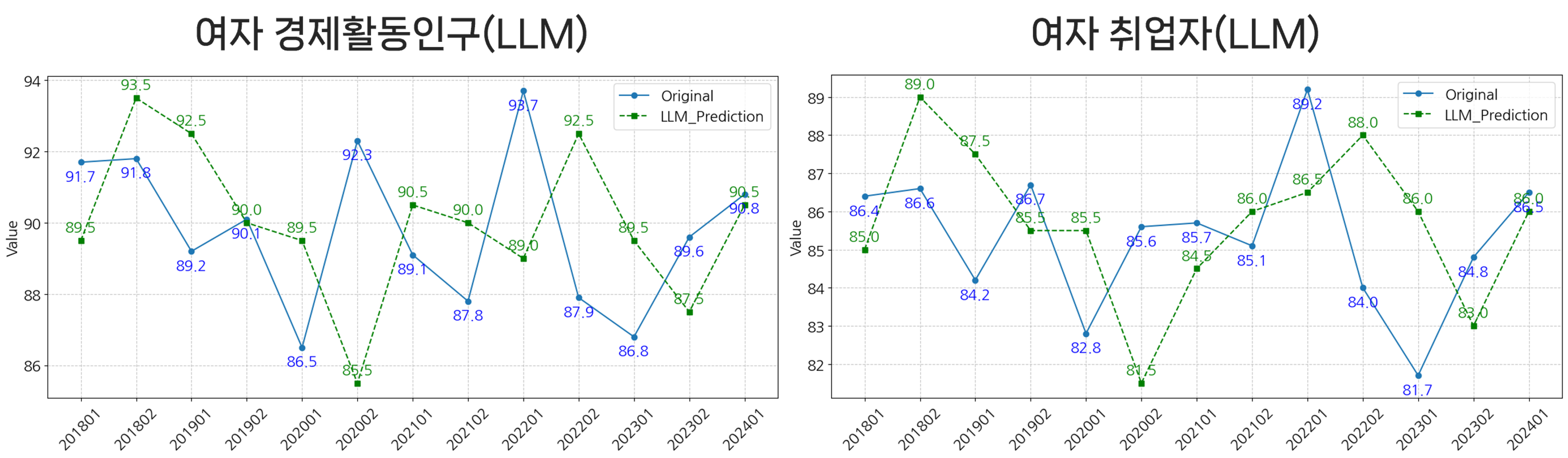
- 시계열 예측 모델과 마찬가지로 LLM을 활용한 예측 결과에서도 여성 관련 변수들의 정확도가 낮게 나타남
7. 예측 결과 비교
- 앞서 학습한 시계열 모델과 LLM의 예측값을 비교한 결과는 다음과 같음
| 활용 모델 | 예측 변수 | MAPE |
|---|---|---|
| 시계열 | 남성 취업자 수 | 1.01% |
| 여성 취업자 수 | 2.53% | |
| 남성 경제활동인구 수 | 1.14% | |
| 여성 경제활동인구 수 | 2.72% | |
| LLM | 남성 취업자 수 | 1.90% |
| 여성 취업자 수 | 2.77% | |
| 남성 경제활동인구 수 | 1.46% | |
| 여성 경제활동인구 수 | 3.00% |
- 모든 변수에 대해 시계열 모델이 LLM 대비 더 낮은 MAPE를 보임
- 이는 LLM이 다양한 정성적 요인들을 포괄적으로 분석할 수 있지만 정확한 수치 예측 능력은 시계열 모델에 비해 상대적으로 제한되어 있기 때문으로 예상됨
8. 결론 및 제언
- 모델을 만들기 위해서는 각 변수들에 대한 도메인 지식이 필요
- 부족한 학습데이터 수로 인해 모델의 일반화 능력에 대한 불확실성 존재
- 추가적인 feature engineering을 통해 예측 모델의 성능을 올릴 수 있을 것으로 기대
- 프롬프트 엔지니어링을 통해 LLM의 예측 성능 향상 기대
- 시계열 모델과 LLM의 상호보완적 특성을 활용한 하이브리드 접근법을 통해 예측 정확도 개선 가능